In 2021, one of the pain points my new team I joined was having was that sticker, emoji, and theme creators needed a way to link their accounts for the purpose of giving recommendations to customers.
For example, let’s consider the company ‘Sanrio’ which owns the intellectual property of Hello Kitty, Gudetama, and Peanuts.
Whenever someone is interested in Hello Kitty stickers, we may want to also want to recommend to the customer other Sanrio products such as Gudetama.
In addition, we can find many examples of collaborations between intellectual properties across different companies, such as the Gundam or LINE friends.
When a customer access the collaboration page of two or more intellectual properties, we want to give recommendations based upon each individual intellectual property.
A major hurdle we need to overcome was that the data for official (large corporations) and creators (smaller, self-published enterprises) were stored in two different databases: SQL and MongoDB respectively.
Therefore, we agreed that we wanted to use a third database whose data is derived from the other two databases.
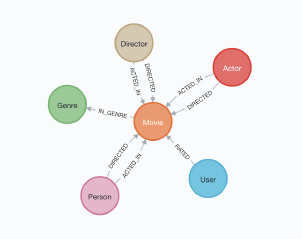
Given this ambiguous context, I started to look into graph databases, because they seemed to be among the best technologies that would allow us to connect entities together while giving us the flexibility to change the schema if need be.
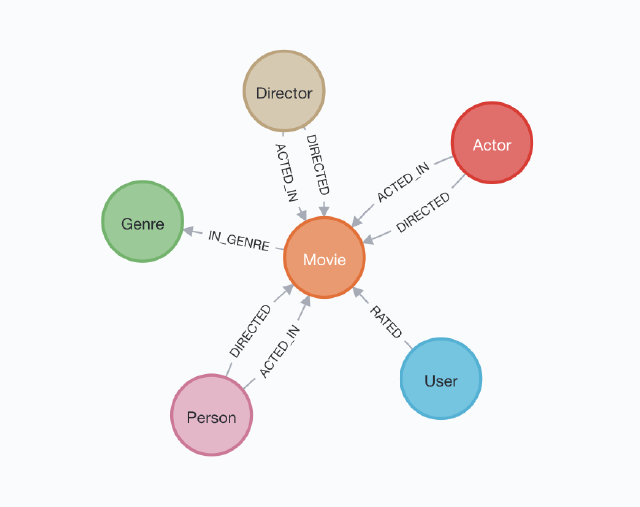
I first looked into Neo4J, which was the one of the first graph databases that comes up when you search on Google.
I was quickly able to write some code with some dummy data and create a graph representation of that data, which you can find below.
public void createCreatorAuthorRelationship(final String creatorId, final String authorId, AuthorType type) {
// To learn more about the Cypher syntax, see https://neo4j.com/docs/cypher-manual/current/
// The Reference Card is also a good resource for keywords https://neo4j.com/docs/cypher-refcard/current/
String createRelationshipQuery = "MERGE (c1:Creator { id: $creator_id })\n" +
"MERGE (a1:Author:" + type.toString() + " { id: $author_id })\n" +
"MERGE (c1)-[:IS_AUTHOR_OF]->(a1)\n" +
"RETURN c1, a1";
Map<String, Object> params = new HashMap<>();
params.put("creator_id", creatorId);
params.put("author_id", authorId);
try (Session session = driver.session(SessionConfig.forDatabase("neo4j"))) {
// Write transactions allow the driver to handle retries and transient errors
Record record = session.writeTransaction(tx -> {
Result result = tx.run(createRelationshipQuery, params);
return result.single();
});
System.out.printf("Created relationship between: %s, %s%n",
record.get("c1").get("id").asString(),
record.get("a1").get("id").asString());
// You should capture any errors along with the query and data for traceability
} catch (Neo4jException ex) {
LOGGER.log(Level.SEVERE, createRelationshipQuery + " raised an exception", ex);
throw ex;
}
}
The above code is a sample of how to create a relationship between author and creator entities in Neo4J!
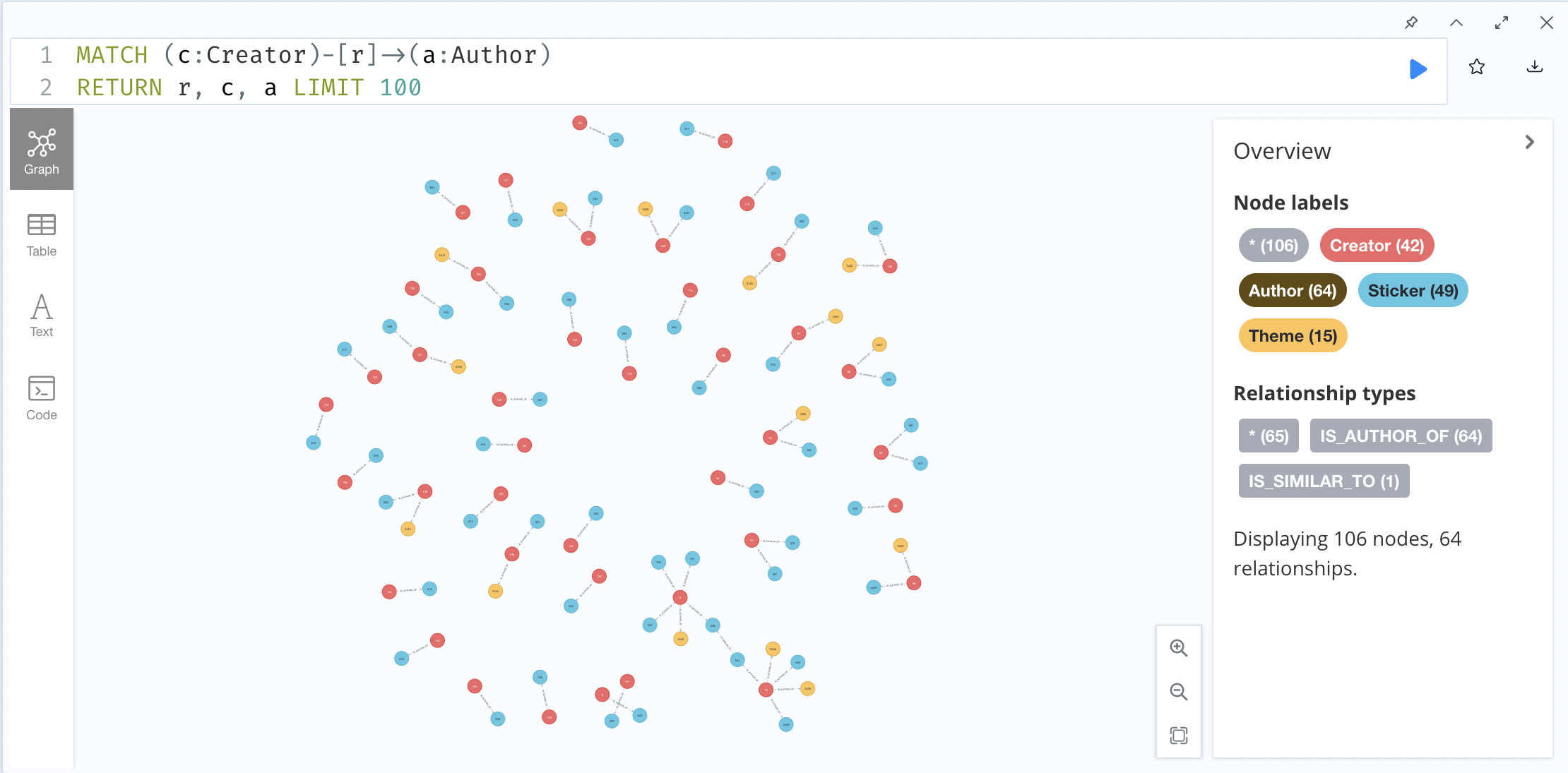
I took some dummy data with 100 entities and created the below graph.
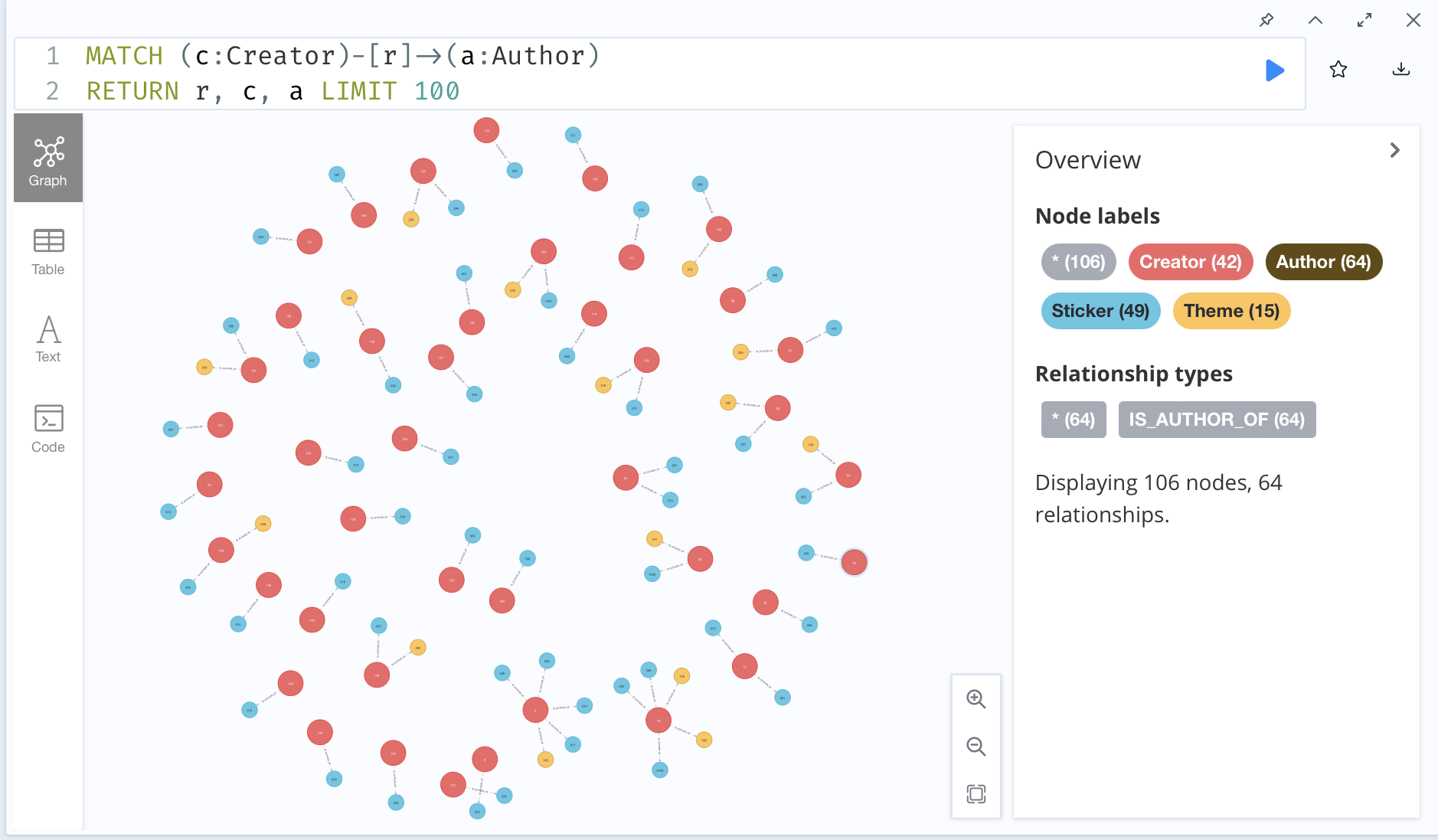
To create a connection between two authors, it is as easy as the following Neo4J statement:
MERGE (a1:Author { id: "538" })
MERGE (a2:Author { id: "553" })
MERGE (a1)-[:IS_SIMILAR_TO]->(a2)
RETURN a1, a2
And the following graph is created:
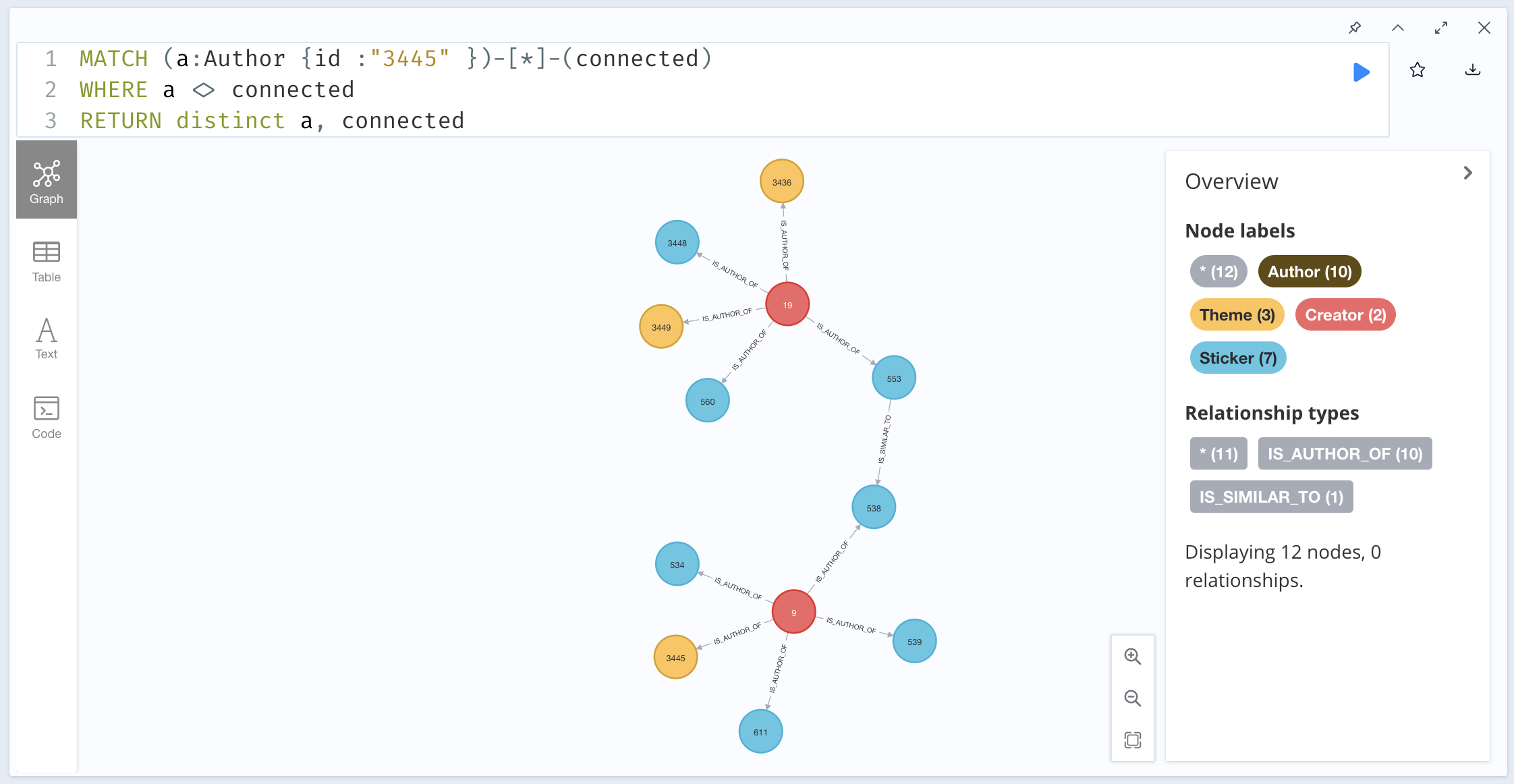
To find all the connected components to an author, the following query is executed:
MATCH (a:Author {id: "3445" }) -[*] - (connected)
WHERE a <> connected
RETURN distinct a, connected
And you can find the graph of the connected components below:
I made a presentation of my findings, which was well received by my department, however we later found out that the cost of Neo4J was too prohibitive for the budget and scope of the project.
And so, I looked into a myriad of different graph databases, and I eventually came across JanusGraph.
Over a period of a month, I created a rough system architecture using JanusGraph, created a graphical representation data using Gelphi, and wrote and delivered another presentation about my findings.
public static void createCreatorAuthorRelationship(JanusGraph graph, final String creatorId, final String authorId, final AuthorType type) {
final JanusGraphTransaction tx = graph.newTransaction();
final Vertex creator = getOrCreateVertex(tx, "CREATOR", "creator_id", creatorId);
final Vertex creation = getOrCreateVertex(tx, type.name(), type.getPropertyIdentifier(), authorId);
creation.addEdge("is_author_of", creator);
tx.commit();
System.out.printf("Created relationship between: %s, %s%n", creatorId, authorId);
}
private static Vertex getOrCreateVertex(final JanusGraphTransaction tx, final String vertexLabel, final String idKey, final String id) {
return tx.traversal()
.V()
.hasLabel(vertexLabel)
.has(idKey, id)
.fold()
.coalesce(unfold(), addV(vertexLabel).property(idKey, id))
.next();
}
The above code is a sample of how to create a relationship between author and creator entities in Janus Graph!
We can draw an edge between two authors with the id “558” and “553” with the following code:
public void createAuthorAuthorRelationship(final String authorId1, final AuthorType type1,
final String authorId2, final AuthorType type2) {
final JanusGraphTransaction tx = graph.newTransaction();
final Vertex vertex1 = getVertex(tx, authorId1, type1);
final Vertex vertex2 = getVertex(tx, authorId2, type2);
vertex1.addEdge("is_similar_to", vertex2);
tx.commit();
System.out.printf("Created relationship between: %s, %s%n", authorId1, authorId2);
}
private Vertex getVertex(final JanusGraphTransaction tx, final String authorId, final AuthorType type) {
return tx.traversal()
.V()
.hasLabel(type.name())
.has(type.getPropertyIdentifier(), authorId)
.next();
}
We can then find all the connected nodes from a single node with this gremlin query and output as a graphML:
TinkerGraph sg = (TinkerGraph)graph.traversal()
.V()
.hasLabel(type.name())
.has(type.getPropertyIdentifier(), authorId)
.repeat(__().bothE()
.where(P.without("a"))
.store("a")
.subgraph("sub")
.otherV()
).until(cyclicPath())
.cap("sub")
.next();
sg.io(IoCore.graphml()).writeGraph("subgraph.xml");
Again this presentation was well received, however an internal security review of a new technology such as JanusGraph would take longer than the expected time to implement(at least six months), so this idea was scrapped.
Going back to the drawing board, I was pushed to solve the same problem using technologies already used within the company, so I looked further into $graphLookup functionality in mongoDB.
Within a couple of weeks, I created a new architecture using mongoDB by referencing this website and these slides and wrote a detailed design document.
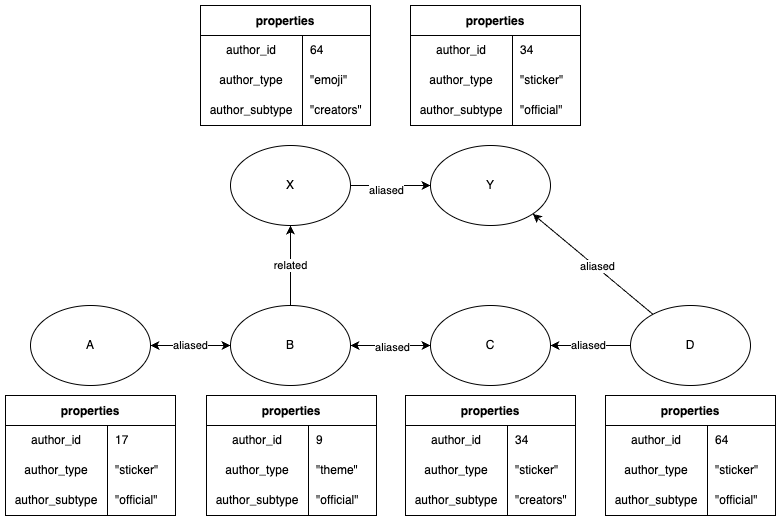
In that new document, defined the schema for vertex and edge below:
Vertex {
labels: ["official", "sticker"],
parents: {
"aliased" : { ObjectId("xxx")}
"related" : { ObjectId("yyy"), ObjectId("zzz") }
},
children: {
"aliased" : { ObjectId("aaa"), ObjectId("bbb"), ObjectId("ccc") }
},
properties: {
author_id: 12,
last_updated_by: "JPxxxx",
last_updated_date: "zzzz-yy-xx aa:bb:cc JST"
}
}
Edge {
labels: ["aliased"],
src: ObjectId("www"),
dest: ObjectId("xxx"),
properties: {
last_updated_by: "JPxxxx",
last_updated_date: "zzzz-yyy-xx aa:bb:cc JST",
}
}
In order to search for connected components, I used the graphLookup feature:
db.vertices.aggregate( [
{
$match: { labels: [$author_type, $author_subtytpe], properties: { "author_id" : $author_id } }
},
$graphLookup: {
"from": “vertices”
"startWith": "$children.aliased"",
"connectFromField": "$children.aliased",
"connectToField": "_id",
"as": “connected_authors”
}
},
])
You can play with the above example using Mongo Playground here
Unfortunately, due to poor economic conditions in the tech industry and restructuring in the company, the project was cancelled.
Hearing this news was hard to hear after putting so much effort in the design, but I really learned so much about graph databases and I would be excited to one day use them in the future.